

Meta has unveiled the Llama 3 family of generative AI models, marking a significant advancement in their open AI model offerings. The release includes two models, the Llama 3 8B and Llama 3 70B, distinguished by their parameter counts of 8 billion and 70 billion, respectively.
How Do the New Models Measure Up?
The company describes these new models as a “major leap” from the previous generation, Llama 2, in terms of their abilities to analyze and generate text. The development involved extensive training on two 24,000 GPU clusters, which Meta claims places these models among the top-performing generative AI models available today for their respective parameter sizes.
Meta supports these claims with performance metrics from several AI benchmarks, including MMLU, ARC, DROP, and others, which measure various capabilities such as knowledge retention, skill acquisition, and reasoning. Despite some ongoing debates about the effectiveness and fairness of these benchmarks, they remain a standard method for evaluating AI models within the industry.
How Does Llama 3 Compare to Other Models?
Llama 3 8B outperforms other open models with similar parameter counts, specifically besting Mistral’s Mistral 7B and Google’s Gemma 7B in a variety of benchmarks including:
- MMLU (Massive Multitask Language Understanding): Measures general knowledge.
- ARC (AI2 Reasoning Challenge): Focuses on the model’s ability to perform complex reasoning.
- DROP (Discrete Reasoning Over Paragraphs): Evaluates reasoning over textual data.
- GPQA: Assesses questions related to biology, physics, and chemistry.
- HumanEval: Tests code generation capabilities.
- GSM-8K: Involves math word problems.
- MATH: Additional mathematics benchmark.
- AGIEval: Designed for problem-solving assessment.
- BIG-Bench Hard: Evaluates commonsense reasoning.
Additionally, the larger Llama 3 70B model shows competitive performance against Google’s flagship Gemini 1.5 Pro on several of these benchmarks and even outperforms some of the models in Anthropic’s Claude 3 series.
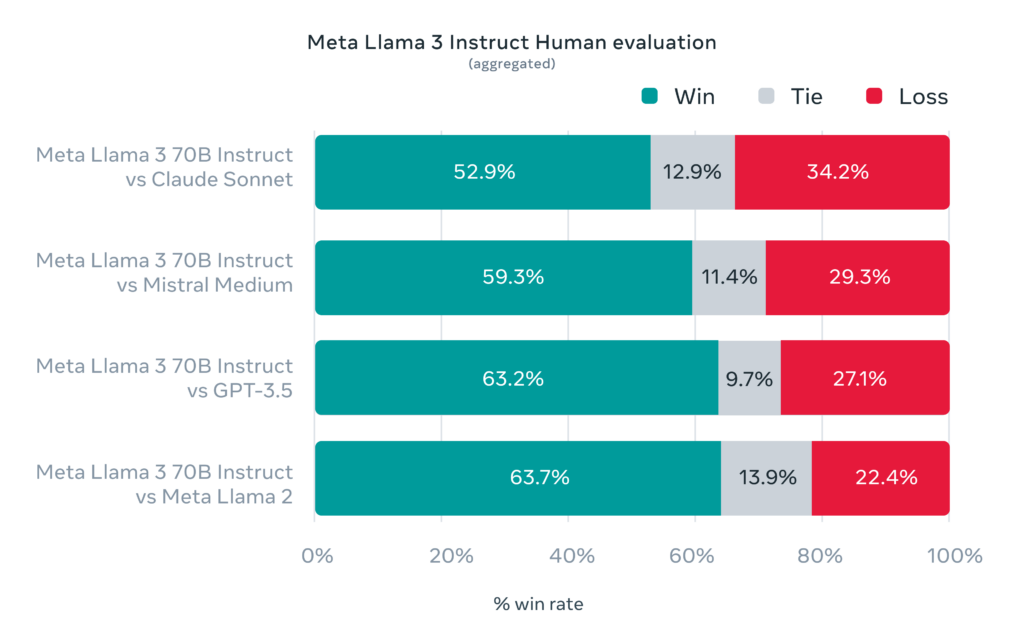
Meta has also developed its own set of benchmarks tailored to specific use cases such as coding, creative writing, and summarization. Here, the Llama 3 70B notably came out on top against competitors like OpenAI’s GPT-3.5 and various models from the Claude series, despite potential biases since Meta designed these tests.
Aside from quantitative improvements, the new Llama models promise enhanced features like increased steerability, reduced refusal rates in answering questions, and higher accuracy in fields such as trivia, history, and STEM. These enhancements are supported by a significantly larger dataset used for training, which comprises approximately 750 billion words, seven times the size of the dataset used for Llama 2. This extensive dataset includes a notable portion of non-English data and synthetic data, which help improve the models’ performance across diverse tasks and languages.
However, Meta has been reticent about the sources of this training data, only noting that it comes from “publicly available sources” and includes a considerable amount of code. The use of synthetic data for training is also notable, as it remains a contentious method within the AI community due to potential performance issues.
How Is Meta Ensuring Safety and Fairness?
In addressing concerns about toxicity and bias—common issues with generative AI models—Meta claims improvements through new data-filtering pipelines and updated AI safety tools, including Llama Guard and CyberSecEval.
Despite these measures, the full performance and safety of Llama 3 models will only be verified through further real-world application and independent testing.
What’s Next for the Llama 3 Models?
The Llama 3 models are currently available for download and are integrated into Meta’s various platforms, including Facebook, Instagram, WhatsApp, Messenger, and the web. They are also set to be hosted on multiple cloud platforms and will eventually be optimized for hardware from several major tech companies.
Despite their availability for research and commercial use, Meta imposes certain restrictions on the use of these models, particularly in training other generative models or in applications by developers with extensive user bases, highlighting the nuanced definition of “open” in this context.
Meta has ambitious plans for the future of the Llama 3 series, including training models with up to 400 billion parameters and enhancing their capabilities to handle multiple languages and modalities. The goal is to expand these models’ effectiveness in understanding and generating not just text but also images and other data types, aiming to align the Llama 3 series with open releases like Hugging Face’s Idefics2.
Related News:
Featured Image courtesy of SOPA Images/LightRocket via Getty Images